基础信息:
- 规格:48核心96线程
- 基础频率:2.90GHz
- 最高加速频率:4.00GHz
- 全核加速频率:3.70GHz
- 最大内存速度:8000MT/S(MRIMM)、6400MT/S(RDIMM)
- 三级缓存:288MiB
- PCIe5.0通道数:136
- 拓展性:1S ONLY
- CPU热设计功率(TDP):350W
更多信息
- CPUID:A06D1
- 步进:B1
- CPU 功率限制 PL1 (长时间)/处理器基本功率 (PBP):功率 = 350.00 W, 时间 = 1.00 sec
- PL1锁定:否
- CPU 功率限制 PL2 (短时间)/最大睿频功率 (MTP):功率 = 420.00 W, 时间 = 11.72 ms
- PL2锁定:否
- 睿频倍频限制:40x (1-24c), 39x (25-40c), 38x (41-44c), 37x (45-48c)
测试数据
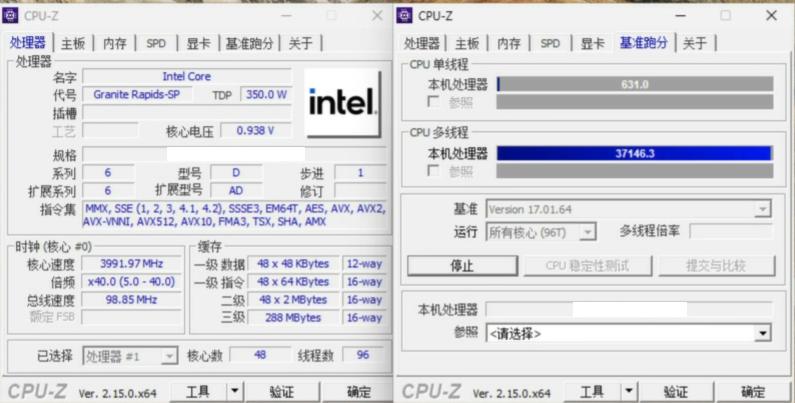
CPU-Z:
Intel(R) MLC(8*RDIMM 6400):
Intel(R) Memory Latency Checker – v3.12
Detected Birch Stream platform, latency optimized mode may need to be turned on to get the best latencies.
Measuring idle latencies for random access (in ns)…
Numa node
Numa node 0 1
0 133.7 155.5
1 146.3 128.0
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 357339.8
3:1 Reads-Writes : 279248.6
2:1 Reads-Writes : 264051.6
1:1 Reads-Writes : 239325.4
Stream-triad like: 266023.0
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0 1
0 175572.2 181096.3
1 176826.3 179603.6
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
==========================
00000 361.14 353731.6
00002 355.76 352229.3
00008 373.20 359898.9
00015 347.20 358266.0
00050 275.49 343528.9
00100 238.53 321878.8
00200 229.04 275478.7
00300 203.00 195857.3
00400 185.15 169860.2
00500 169.87 140104.4
00700 156.18 103344.3
01000 146.12 74164.2
01300 142.67 57827.2
01700 139.00 44737.2
02500 137.63 30828.0
03500 136.58 22292.9
05000 134.55 15782.3
09000 133.65 8984.6
20000 133.47 4319.2
Measuring cache-to-cache transfer latency (in ns)…
Using small pages for allocating buffers
Local Socket L2->L2 HIT latency 140.3
Local Socket L2->L2 HITM latency 142.2
Intel(R) MLC(8*MCRDIMM 8000):
Intel (R) Memory Latency Checker – v3.12
Detected Birch Stream platform, latency optimized mode may need to be turned on to get the best latency.
Measuring idle latencies for random access (in ns)…
Numa node
Numa node 0 1
0 135.9 151.3
1 138.3 113.3
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
All Reads : 454256.0
3:1 Reads-Writes : 398407.4
2:1 Reads-Writes : 384581.6
1:1 Reads-Writes : 362808.2
Stream-triad like : 381808.2
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0 1
0 227686.1 198141.3
1 194116.2 228305.8
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
====================
00000 218.33 453338.0
00002 225.37 454041.7
00008 277.45 469558.8
00015 265.36 468629.1
00050 213.87 455898.8
00100 183.28 415891.2
00200 177.95 301810.3
00300 156.94 207527.1
00400 144.55 172450.9
00500 136.94 141688.8
00700 129.33 104296.8
01000 124.62 74435.4
01300 122.71 54838.6
01700 121.39 45155.7
02500 120.52 31167.8
03500 119.59 22543.3
05000 119.00 16009.9
09000 113.22 91609.1
20000 117.60 4420.8
Measuring cache-to-cache transfer latency (in ns)…
Using small pages for allocating buffers
Local Socket L2->L2 HIT latency 138.2
Local Socket L2->L2 HITM latency 141.1

发表回复